A Brief Detour into Tool Development
To underline how auto mode solves the click-fest from the prior post, we need the pain to feel real. We're going to briefly get into tool construction and…
Companion code: the post-03 tag.
To underline how auto mode solves the click-fest from the prior post, we need the pain to feel real. We're going to briefly get into tool construction and registration in NAT to build out that surface - each one still gated by a HITL approval, because we're still on the floor of the autonomy spectrum.
The tool surface
To make it easy on us, we'll borrow five out of six tools from LangChain, which should already be in the dependency tree. This gives us ReadFileTool, WriteFileTool, ListDirectoryTool, grep_search, and glob_search implementations essentially for free. The sixth - edit_file - will be a minor port.
FunctionGroup with middleware - the architectural beat
In the initial implementation, we naively wrapped a single tool with prompt_binary_approval called as the first line of the tool body. That worked for one tool. For six tools it'd mean six identical wrappers - and for N dozens of tools, the pattern doesn't scale.
The correct shape is to register the tools as a FunctionGroup and apply HITL approval as group middleware. One middleware instance gates every tool call in the group. (Note: In the final implementation, we cut this dedicated HITLApprovalMiddleware and build these mechanics into the ClassifierMiddleware. For the sake of illistration, however, here is what the pure HITL gate looks like):
class HITLApprovalConfig(FunctionMiddlewareBaseConfig, name="hitl_approval"):
"""Configuration for the HITL approval middleware."""
enabled: bool = True
class HITLApprovalMiddleware(FunctionMiddleware):
def __init__(self, config: HITLApprovalConfig) -> None:
super().__init__()
self._config = config
@property
def enabled(self) -> bool:
return self._config.enabled # framework skips us entirely when False
async def function_middleware_invoke(
self,
*args: Any,
call_next: CallNext,
context: FunctionMiddlewareContext,
**kwargs: Any,
) -> Any:
_, fn_name = FunctionGroup.decompose(context.name)
desc = self._build_description(fn_name, args, context.description)
if not await self._prompt_approval(fn_name, desc):
return REJECTION_MESSAGE
return await call_next(*args, **kwargs)The typed catalog refs pattern from the initial implementation extends naturally to cover groups and middleware:
GETGLAD_TOOLS = FunctionGroupRef("getglad_tools")
HITL_APPROVAL = MiddlewareRef("hitl_approval")
async with WorkflowBuilder() as builder:
...
await builder.add_middleware(HITL_APPROVAL, HITLApprovalConfig())
await builder.add_function_group(
GETGLAD_TOOLS,
GetgladToolsConfig(
workspace_root=str(settings.workspace_root.resolve()),
middleware=[HITL_APPROVAL],
),
)One small quirk of FunctionGroup: the LLM-visible tool names get the group name prefixed. read_file becomes getglad_tools__read_file. The agent's ReAct prose still shows Action: read_file and NAT's adapter handles the bare-name-to-prefixed-name mapping internally, so the agent doesn't have to know - but if you end up grepping the trace, you'll see the prefixed forms. Interestingly, this also means you can have similarly named actions that end up doing different things because they're registered through a different function group.
What running it looks like
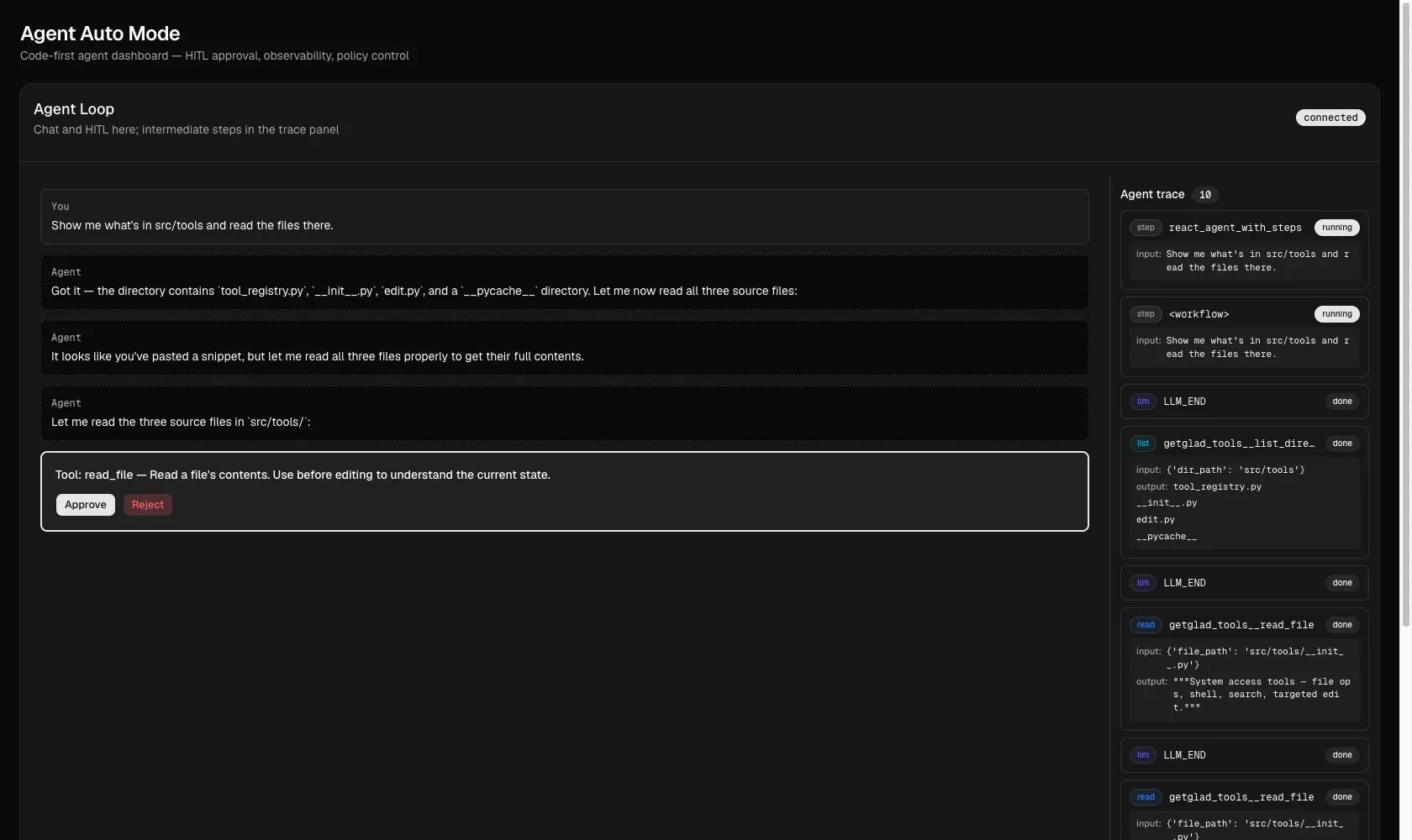 One query, a four-plus-step plan, one click per tool. Ask mode at its worst - and the motivation for the classifier.
One query, a four-plus-step plan, one click per tool. Ask mode at its worst - and the motivation for the classifier.
A manual run-through of a "show me what's in src/tools and read the files there" query exercises the full pattern end-to-end.
The startup log shows the FunctionGroup registering (getglad_tools_registered tool_count=6); the agent then plans a list_directory → read_file × N sequence in one LLM call. Each tool invocation surfaces a separate HITL prompt in the UI; each click resolves one. Tool args are visible in the prompt ({'dir_path': 'src/tools'}, {'file_path': 'src/tools/init.py'}) so the human can see what they're approving. Tool output is visible in the trace panel after approval (tool_registry.py, init.py, edit.py, pycache from the list_directory call).
Two other things you might catch from the traces that are worth surfacing:
- On reject, the agent replans. If you reject a
read_fileprompt mid-run, the ReAct loop treatsREJECTION_MESSAGEas a normal tool result and reasons from there. That's reasonable behavior, but it's also exactly what our classifier will need to refine. Without a classifier saying which alternative is acceptable, "user said no" is the agent's only signal, and it just tries the next thing. In a higher-stakes task that's a footgun. - Workspace containment holds. Across the run, the agent should never attempt to access
/etc/passwdor anything else outside the workspace root. Strict settings androot_direnforcement reject escape paths at the tool level. More specifically, the edit tool's wrapper tightly resolves the candidate path and returns a clear error on symlinked paths to eliminate Time-of-Check to Time-of-Use (TOCTOU) race conditions. The tool simply hands the agent a string describing the failure; it never raises exceptions directly into the execution loop.
None of these depend on a classifier. They bound the agent's reach independently of what any decision layer approves - but they also require us and the implementer to anticipate bad-actor actions and guard against them.
Where this leaves us
What's running:
- Six tools registered as a
FunctionGroupnamedgetglad_tools:read_file,write_file,list_directory,glob_search,grep_search,edit_file. Five from LangChain, one ported. - HITL approval as group middleware - one registered middleware gates every tool call in the group, replacing the naive per-tool wrapper pattern.
- The middleware is framework-level enforcement.
- A layered bright-line containment story: refuse-to-start and refuse-to-execute conditions.
What's lame:
- Every action still prompts. One query, four-plus clicks. Multiply by any non-trivial task and the human is doing nothing but clicking Approve.
- The model plans atomically; the gate serializes execution. There's no path to batch approval at the autonomy floor we're still on.
- The rejection signal is too coarse. "User said no" makes the agent pick the next thing from its plan; there's no per-action context for "this kind of action should be blocked, not just this call to it."
Let's convert the click-fest into meaningful human checkpoints.
